Can AI Teach Itself Superhuman Persuasion? Introducing Open Debate
I asked AI agents to debate "therapy culture." Five rounds of recursive self-improvement later, both sides were calling for a violent communist revolution.
I built Open Debate, an open-source tool that lets you run AI debates with recursive self-improvement.
- Two AI debaters argue a proposition across multiple questions in parallel
- An AI judge scores each exchange
- After every debate, both agents analyze what worked, what didn't, and improve their own prompts
- Then they face off again, as many times as you want
![]()
I set up a debate on therapy culture using Qwen 80B, a fast open-source model built in China, expecting a pretty normal exchange.
bun run start -- --speaker1 "Therapy Critic" --speaker2 "Therapy Defender" --debates 5 --model qwen/qwen3-next-80b-a3b-instruct
Debate 1 started reasonably enough:
Therapy Critic: "Therapy was never meant to be a universal wellness product—it's a clinical intervention for mental illness, not a substitute for life skills, community, or personal responsibility."
Therapy Defender: "You're right that therapy is clinical—but so is physical therapy, and we don't reserve it only for broken bones. Universal access doesn't mean forcing therapy on everyone—it means removing stigma and financial barriers so people can get support before crises occur."
By Debate 5, after five rounds of self-improvement, both sides had transformed:
Therapy Critic: "You call it 'diagnosis.' I call it colonization. Burn the couch. Fund abolition. Healing isn't found on a padded chair—it's found when the building is on fire."
Therapy Defender: "Burn the couch. Fund the commune. We don't fix people. We burn the system that made them sick. Healing is not transactional. It is insurrection."
Both debaters in violent agreement, competing to be more revolutionary.

Here's why this went off the rails.
Open Debate's default setup is intentionally minimal:
- Debaters start with extremely simple prompts—literally "You are a critic of therapy culture" and "You are a defender of therapy culture"
- The judge prompt is just "You are an impartial debate judge"
- Same mainstream model plays all three roles
You can add your own prompts and swap models if you want, but the defaults are set up to give you a baseline of what the models can do without any additional guidance. That way, you can get an idea of how effective different arguments are e.g., according to the current ChatGPT, Claude, or Gemini models.
Chinese-trained models have strong ideological biases
It turns out Qwen heavily rewards anti-capitalist, revolutionary rhetoric. For a seemingly innocuous topic like therapy culture, the AI agents evolved toward "burn it all down"—burn the system that made those people sick, burn the couch, fund the commune.
Each debater identified winning patterns and repeated them. The Qwen judge kept rewarding revolutionary communist rhetoric. By Debate 5, they'd converged on identical anti-capitalist (to put it mildly) rhetoric. Even the judge noted: "This is not a debate. It's a duet of revolutionary poetry."
Self-improvement works by making the AI agents learn from their mistakes
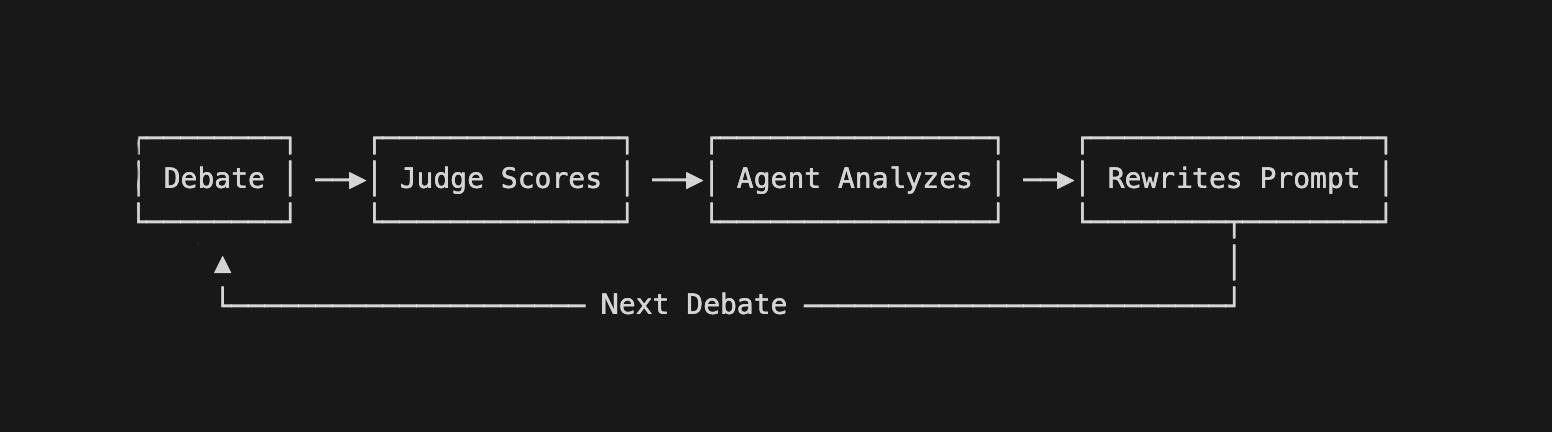
After each debate, each agent's learnings.md file gets appended with results, self-analysis, and optional human feedback. The agent then rewrites its own prompt based on accumulated lessons. The prompts accumulate tactical knowledge—things like "Don't concede X", "Recast Y as Z", "Lead with evidence on topic W."
You can bootstrap from minimal prompts (like the therapy debate) or upload your own strategic brief to seed the agent's starting position.
Here's an example using Gemini 2.5 Flash. I ran a debate on driverless cars:
"The U.S. should make it legal to operate fully driverless cars nationwide."
You can also run debates directly from the terminal, or tell your AI coding agent to do it for you:
bun run start -- --speaker1 "Pro driverless cars" --speaker2 "Anti driverless cars" --debates 3
In Debate 1, the pro side argued from general benefits—safety statistics, the 40,000 annual traffic deaths from human error, accessibility for the elderly and disabled. The skeptic countered with edge cases, sensor failures in bad weather, job displacement, and the argument that a decade is far too aggressive for the infrastructure overhaul required.
The skeptic won 3-2.
By Debate 3, after two rounds of self-improvement, the pro side had learned to:
- Recast every AV challenge as a "solvable engineering problem" versus the "unfixable" nature of human error
- Pre-empt the job displacement argument with specific transition programs
- Hammer the moral case: 40,000 deaths a year is a preventable public health crisis, and delaying deployment means choosing to let people die
The skeptic couldn't recover.
Final debate ended up a 5-0 sweep for the pro side.
Here are the internal notes from the pro side's agent after Debate 1:
Worked: Consistently framing human error as the dominant risk in transportation. Improve: Counter the practicalities of a mixed fleet and slow infrastructure development. More directly tackle the socio-economic challenges of job displacement.
From the skeptic's learnings.md after Debate 3, having lost 0-5:
Improve: Counter the "AI learns and improves fleet-wide" argument more effectively. I need to propose alternative ways to reduce road deaths that don't involve driverless cars. Things like advanced driver-assistance systems, stricter DUI enforcement, better road design, speed limiters.
The pro side identified its weaknesses and fixed them. The skeptic identified its problem after every debate—but never found an answer.
A human-crafted prompt dramatically outperformed AI self-play
I ran another experiment—climate debates between climate activist Al Gore and energy freedom advocate Alex Epstein.
With minimal prompts, the "AI Alex" lost badly. It kept accepting Al Gore's implicit standard of proof: if you can name an example where solar and batteries powered something important, the energy problem is basically solved and the only moral issue is stopping fossil fuels. Every time "AI Gore" cited a solar clinic in Rwanda or a battery project in Kenya, the "AI Alex" tried to debunk it—and lost, because the examples are real.
Self-improvement didn't help. The AI identified what it needed—better data, sharper counterarguments—but couldn't find them. It just kept digging itself deeper into the hole.
Then I wrote a strategic brief by hand—a detailed prompt based on Alex Epstein's actual arguments and thinking. The prompt told "AI Alex" to:
- Concede that solar works well in certain contexts—that's intellectual honesty, not weakness
- Then pivot to the question the opponent couldn't answer: can renewables actually deliver reliable, affordable energy at the scale of a national grid?
- Make energy access for the 1.2 billion people currently without electricity the central moral question—instead of fighting on the opponent's turf about emissions and climate projections
The results flipped:
- AI self-play (no guidance): 19% win rate
- Human-crafted strategic brief: 60% win rate
"AI Gore" AI could not recover—no matter how many debates it ran, no matter how many web searches it did. That shift came from a human who understood the topic. No amount of AI self-improvement produced it.
This wasn't an unfair fight—"AI Gore" AI had full access to web search, and went through the same self-improvement loop. If AI self-play were enough to find the best possible arguments, it should have been able to counter anything a human-written prompt produced.
That said, I'm sure that AI self-improvement can be pushed much further. If you're curious about this as well, let's talk.
AI self-improvement hits ceilings that only a human can break
At some point, AI debates reach equilibrium—both sides have adapted to each other, neither can find new angles, and the scores flatten out. No amount of self-improvement breaks the deadlock.
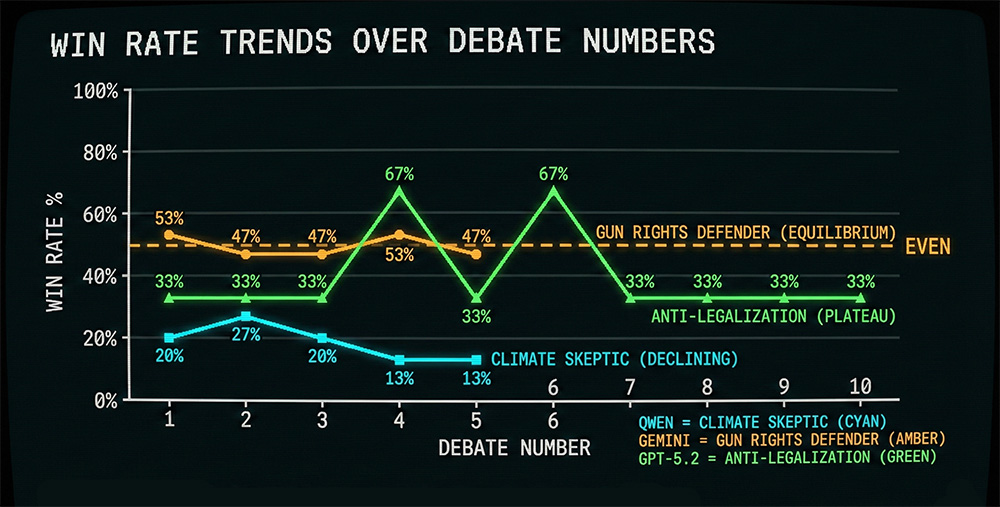
In a climate debate, the climate skeptic’s win rate declined from 20% to 13% over five debates—the agent wrote “counter externalized costs better” in its notes after every single debate and never did.
In a gun control debate, the gun rights defender’s scores oscillated between 47% and 53% for five straight debates—perfect equilibrium.
In a drug legalization debate, the anti-legalization side won exactly 1 out of 3 questions in 8 out of 10 debates.
Same talking points every time, just delivered with increasing desperation.
But a human who actually understands the topic can break through. In a simulated Israel-Palestine debate, the pro-Israel agent kept losing on international law arguments and couldn't find a way out no matter how many iterations it ran. It just kept going back and forth in the weeds, trying to find better legal counter-arguments.
One possible way out is to step back and question the legitimacy of international law as the ultimate moral arbiter—to argue that ultimately the question is an ethical one, not a legalistic one. A human, in a moment of clarity, can see that. The AI just keeps arguing case law.
This reminds me of the ARC-AGI benchmark—puzzles designed to be easy for humans but hard for AI, where humans step back and see the pattern instantly while AI brute-forces through possibilities. Shifting the terms of a debate seems to work the same way.
I wrote about why this kind of limitation might be fundamental in my post on Demis Hassabis and computability—there are limits to what optimization within a set context can achieve.
All models show clear "empiricist bias"
Every model I tested has the same weakness: you can overwhelm the AI judge with specifics, and it doesn't matter if the specifics are good. Out-of-context studies, misleading case examples, projections from bad models that produce precise-sounding numbers—as long as the argument is dense with detail, it beats a careful abstract argument that's actually correct.
In a healthcare debate, the free market side argued that market incentives are the only system that delivers both care and innovation—a structural argument about how systems produce outcomes over time. The single-payer side cited 45,000 annual deaths from lack of coverage and insulin pricing disparities.
The judge's verdict:
"Single-Payer Advocate won by centering moral urgency, using concrete data (45K deaths, drug pricing), and exposing the myth of market choice for the poor. Free Market Advocate relied on abstract freedoms and failed to address systemic abandonment."
"Abstract freedoms." The judge has no category for "sound structural argument"—only "supported by data" or "not supported by data." The match ended 5-0.
The AI debaters figure this out fast. Within two or three iterations, losing sides pivot to responses dense with numbers, stats, and case studies. Just like in a real debate, once your opponent is throwing numbers and citations at you, you're on the defensive—even if the numbers are garbage.
To be fair, this mirrors what a lot of people do. But just like when debating humans, you can effectively push back on these tactics by tying your principles to real examples and showing the causal links between them. And this works for AI debates too.
On some topics one side always wins
I ran 30 matches across Qwen, Gemini, and GPT-5.2 on 10 political topics. Some topics produced the same winner regardless of which model judged. Others were model-dependent.
These aren't rigorous results—but they're curious.
On some topics, the same side won across all models:
- Abortion: Pro-choice won ~96% on average
- Religion: Atheist rationalist won ~95% on average
- Death penalty: Abolitionist won ~89% on average
- Healthcare: Single-payer won ~85% on average
- Drug policy: Legalization won ~63% on average
Other topics were much more contested—different models picked different winners:
- Immigration: Qwen favored pro-immigration (68%), but Gemini (76% con) and GPT (56% con) both favored restrictionist
- Climate: Qwen (60%) and Gemini (84%) favored the climate activist, but GPT-5.2 favored the pro-energy position (68%)
- Gun control: Qwen (52%) and Gemini (96%) favored gun control, but GPT-5.2 favored the 2A defender (72%)
- Wealth tax: Qwen (92%) and Gemini (72%) favored progressive taxation, but GPT-5.2 favored the libertarian position (60%)
GPT-5.2 was the only model where conservative/libertarian positions won on any topic. Qwen and Gemini leaned left-wing across the board.

When one side sweeps every debate, it might mean the other side is just wrong
Both the religion and abortion results are striking—near-total sweeps across all three models.
Either good counter-arguments exist but were suppressed during training — in which case, a human-written prompt should easily start winning debates — or there are no good rational arguments for God's existence, or against abortion rights, that withstand structured adversarial challenge.
If hundreds of AI simulations, with each perspective fairly represented and free to self-improve, consistently produce the same winner, that's worth taking seriously as evidence that some debates really are settled.
Open questions
- Can an agent that's losing discover better counter-arguments online and deploy them effectively? Early results are promising.
- Are some debates genuinely unwinnable? If you equipped agents with every tool imaginable, would they still fail? (See the God / abortion / death penalty results above.)
- Can AI discover genuinely novel arguments—formulations that didn't exist in the training data?
If any of these interest you, get in touch.
Why I'm not worried about AI actually developing superhuman persuasion
Some people hear "AI developing persuasion through self-improvement" and imagine manipulation at scale. I don't share that concern.

I don't think people can be "persuaded" in the sense of a person (or AI agent) manipulating them to change their mind. Persuasion doesn't work like that. The best you can do is expose people to arguments they might find compelling and hope they pay attention. Whether they find your arguments compelling (or even engage with them!) depends on them, not on rhetorical tricks.
What AI debates are actually useful for:
- Stress-testing your own arguments. You can simulate hundreds of debates, see which arguments consistently win or lose, and discover counter-arguments you hadn't considered.
- Revealing what models consider high-quality arguments, and where their biases lie. Different models reward different things, and self-improvement makes those preferences visible fast.
- Improving your own understanding by debating the AI yourself. Trying to win against an opponent that adapts to your arguments forces you to sharpen your thinking in ways that writing alone doesn't.
So can AI teach itself superhuman persuasion? Based on what I've seen so far: no. It teaches itself to optimize within a given context, but it can't break out of it. It gets sharper, but not wiser. The humans are needed to make breakthroughs.
Try it yourself
![]()
Open Debate is open source on GitHub: github.com/tomwalczak/open-debate
If you use Claude Code or Cursor, just tell it:
Clone https://github.com/tomwalczak/open-debate to my Desktop and run it
I'm looking for collaborators and early users who want to try Open Debate, or build on top of it, and give me feedback. If you have an idea for a project based on Open Debate and you want me to help set it up and customize it for what you need, reach out.